
lxml.html¶
Разбор HTTP ответа¶
Довольно легко распарсить HTML код полученный при помощи lxml. Как только мы преобразовали данные в дерево, можно использовать XPath для их извлечения.
import requests
from lxml import html
response = requests.get('http://ya.ru')
# Преобразование тела документа в дерево элементов (DOM)
parsed_body = html.fromstring(response.text)
# Выполнение xpath в дереве элементов
print(parsed_body.xpath('//title/text()')[0]) # Получить title страницы
print(parsed_body.xpath('//a/@href')) # Получить аттрибут href для всех ссылокПример извлекает название HTML страницы и все ссылки найденные в этом документе.
Яндекс
['https://mail.yandex.ru', '//www.yandex.ru']Скачиваем все изображения со страницы¶
Следующий скрипт скачает все изображения и сохранит их в директории
downloaded_images/. Только сначала не забудьте создать соответствующий
каталог. Чтобы сформировать полный путь по относительным ссылкам используется
функция urljoin() из стандартного модуля a
urllib.parse.
# standard library
import sys
from pathlib import Path
from urllib.parse import urljoin
# third-party
import requests
from lxml import html
response = requests.get('http://imgur.com/')
parsed_body = html.fromstring(response.text)
# Парсим ссылки с картинками при помощи XPath
images = parsed_body.xpath('//img/@src')
if not images:
sys.exit("images Not Found")
# Конвертирование всех относительных ссылок в абсолютные
images = [
urljoin(response.url, url)
for url in images
]
print('Found {} images'.format(len(images)))
# Скачиваем только первые 10
for url in images[0:10]:
r = requests.get(url)
target = Path(
'downloaded_images/{}'.format(
url.split('/')[-1] # file name from URL
)
)
target.write_bytes(r.content)После выполнения скрипта в каталоге окажутся скачанные изображения.
CSS selector¶
Селектор определяет, к какому элементу применять то или иное CSS правило. При помощи селекторов можно делать выборки дерева объектов в HTML документе.
Пример ниже показывает, как использовать CSS селекторы используя дерево элементов HTML документа, полученного при помощи библиотеки lxml.
# standard library
from io import StringIO
# third-party
import requests
from lxml import html
r = requests.get('http://ru.arf.ru/')
print(r.encoding) # Кодировка по умолчанию ISO-8859-1
r.encoding = 'cp1251' # Указываем настоящюю кодировку документа
# Формируем дерево элементов
root = html.parse(
StringIO(r.text)
).getroot()
# Выбираем ссылки внутри тегов <td> выровненных по центру
links = root.cssselect('td[align=CENTER] > a')
for item in links:
print(
item.get('href') # печатаем значение атрибута href
)
print()
# Выбираем все изображения
images = root.cssselect('img')
for item in images:
print(
item.get('src'), # печатаем значение атрибута src
html.tostring(item) # и сам элемент
)Результат выполнения:
$ python parse.py
ISO-8859-1
/
/Ludi/index.html
/Hrono/index.html
/Svid/index.html
/Links/index.html
mailto:sova@arf.ru
/Ludi/index.html
/Hrono/index.html
/Svid/index.html
/Links/index.html
mailto:sova@arf.ru
/Pict/ru.png b'<img src="/Pict/ru.png" height="80" width="120" alt="RU History Logo" border="0">'
/Pict/line.png b'<img src="/Pict/line.png" height="3" width="550" alt="divider">\r\n '
/Pict/line.png b'<img src="/Pict/line.png" height="3" width="550" alt="divider">\r\n 'Фильтры¶
lxml имеет множество инструментов для обработки полученных данных. Возьмем ради эксперимента один из самых старых сайтов http://infocity.kiev.ua, дата регистрации 1999 год.
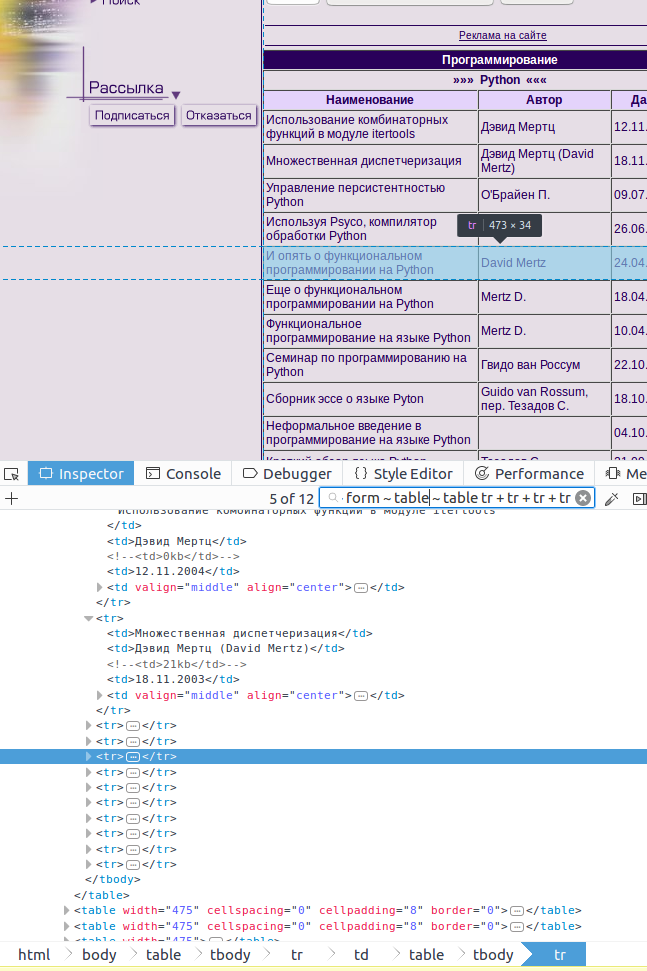
Парсинг сайта http://infocity.kiev.ua
По понятным причинам он использует табличную верстку. Пример ниже показывает как выбрать из таблицы «Программирование» все строки, при помощи смежных элементов в CSS селекторе.
# standard library
from io import StringIO
# third-party
import requests
from lxml import html, etree
r = requests.get('http://infocity.kiev.ua/section51.php')
print(r.encoding) # ISO-8859-1
r.encoding = 'cp1251'
root = html.parse(
StringIO(r.text)
).getroot()
# Выбираем нужную таблицу через смежные селекторы и записи этой таблицы начиная
# с 4 строки
rows = root.cssselect('table ~ form ~ table ~ table tr + tr + tr + tr')Далее будем работать только с первой строкой таблицы.
item = rows[0]
# Печатаем первый элемент результата поиска
print(
html.tostring(
item,
encoding='unicode'
)
)
print()
'''
<tr>
<td>Использование комбинаторных функций в модуле itertools</td>
<td>Дэвид Мертц</td>
<!-- <td>0kb</td> -->
<td>12.11.2004</td>
<td align="center" valign="middle">
<table cellpadding="0" cellspacing="0" style="margin:0px">
<tr>
<td valign="middle">
<a href="prog/python/content/python020.phtml" target="_top"><img src="images/open.gif" border="0" width="17" height="17"></a>
</td>
<td valign="middle">
<a href="prog/python/content/python020.phtml" target="_blank"><img src="images/nopen.gif" border="0" width="17" height="17"></a>
</td>
</tr>
</table>
</td>
</tr>
'''Метод text_content отбрасывает все тэги и оставляет только содержимое.
# Печатаем только текст
print(item.text_content().strip())
print()
'''
Использование комбинаторных функций в модуле itertools
Дэвид Мертц
12.11.2004
'''Для комплексной фильтрации есть мощный класс Cleaner, который позволяет
задать настройки фильтра и многократно применять их к разным элементам.
from lxml.html.clean import Cleaner
cleaner = Cleaner(
scripts=True, # Удаляет все js скрипты <script>
comments=True, # Удаляет все комментарии
allow_tags=['br', 'td', 'tr', 'img'], # Список тэгов которые не нужно удалять
remove_unknown_tags=False
)
print(
cleaner.clean_html( # применяем фильтр
html.tostring(
item,
encoding='unicode'
)
)
)
print()
'''
<tr>
<td>Использование комбинаторных функций в модуле itertools</td>
<td>Дэвид Мертц</td>
<td>12.11.2004</td>
<td align="center" valign="middle">
<tr>
<td valign="middle">
<img src="images/open.gif" border="0" width="17" height="17">
</td>
<td valign="middle">
<img src="images/nopen.gif" border="0" width="17" height="17">
</td>
</tr>
</td>
</tr>
'''Более того, наш элемент тоже является деревом элементов, поэтому мы можем производить в нем поиск. Попробуем выбрать все элементы <td> выравненные по центру.
# Ищем элемент td выровненный по центру
item_td = item.cssselect('td[align=center]')[0]
print(
html.tostring(
item_td,
encoding='unicode'
)
)
print()
'''
<td align="center" valign="middle">
<table cellpadding="0" cellspacing="0" style="margin:0px">
<tr>
<td valign="middle">
<a href="prog/python/content/python020.phtml" target="_top"><img src="images/open.gif" border="0" width="17" height="17"></a>
</td>
<td valign="middle">
<a href="prog/python/content/python020.phtml" target="_blank"><img src="images/nopen.gif" border="0" width="17" height="17"></a>
</td>
</tr>
</table>
</td>
<td>
'''Атрибуты корневого тэга доступны в свойстве attrib. Вызовем метод
clear, чтобы их очистить.
# Удаляем все атрибуты корневого тэга
item_td.attrib.clear()
print(
html.tostring(
item_td,
encoding='unicode'
)
)
print()
'''
<td>
<table cellpadding="0" cellspacing="0" style="margin:0px">
<tr>
<td valign="middle">
<a href="prog/python/content/python020.phtml" target="_top"><img src="images/open.gif" border="0" width="17" height="17"></a>
</td>
<td valign="middle">
<a href="prog/python/content/python020.phtml" target="_blank"><img src="images/nopen.gif" border="0" width="17" height="17"></a>
</td>
</tr>
</table>
</td>
'''Элемент содержит много разных свойств, например tag позволяет изменить
название тэга.
# Меняем название тэга
item_td.tag = 'my_custom_tag_td'
print(
html.tostring(
item_td,
encoding='unicode'
)
)
print()
'''
<my_custom_tag_td>
<table cellpadding="0" cellspacing="0" style="margin:0px">
<tr>
<td valign="middle">
<a href="prog/python/content/python020.phtml" target="_top"><img src="images/open.gif" border="0" width="17" height="17"></a>
</td>
<td valign="middle">
<a href="prog/python/content/python020.phtml" target="_blank"><img src="images/nopen.gif" border="0" width="17" height="17"></a>
</td>
</tr>
</table>
</my_custom_tag_td>
'''Модуль etree содержит функции преобразования дерева.
strip_tags удаляет список тэгов но оставляет их содержимое.
# Удаляем список тегов, не трогая их содержимое
etree.strip_tags(item_td, 'a', 'b', 'c')
print(
html.tostring(
item_td,
encoding='unicode'
)
)
print()
'''
<my_custom_tag_td>
<table cellpadding="0" cellspacing="0" style="margin:0px">
<tr>
<td valign="middle">
<img src="images/open.gif" border="0" width="17" height="17">
</td>
<td valign="middle">
<img src="images/nopen.gif" border="0" width="17" height="17">
</td>
</tr>
</table>
</my_custom_tag_td>
'''strip_elements удаляет список тэгов вместе с содержимым.
# Удаляем тэг со всеми потрахами
etree.strip_elements(item_td, 'td')
print(
html.tostring(
item_td,
encoding='unicode'
)
)
print()
'''
<my_custom_tag_td>
<table cellpadding="0" cellspacing="0" style="margin:0px">
<tr>
</tr>
</table>
</my_custom_tag_td>
'''Полный код:
# standard library
from io import StringIO
# third-party
import requests
from lxml import html, etree
r = requests.get('http://infocity.kiev.ua/section51.php')
print(r.encoding) # ISO-8859-1
r.encoding = 'cp1251'
root = html.parse(
StringIO(r.text)
).getroot()
# Выбираем нужную таблицу через смежные селекторы и записи этой таблицы
# начиная с 4 строки
rows = root.cssselect('table ~ form ~ table ~ table tr + tr + tr + tr')
print(len(rows))
print()
item = rows[0]
# Печатаем первый элемент результата поиска
print(
html.tostring(
item,
encoding='unicode'
)
)
print()
# Печатаем только текст
print(item.text_content().strip())
print()
# http://lxml.de/api/lxml.html.clean.Cleaner-class.html#_tag_link_attrs
from lxml.html.clean import Cleaner
cleaner = Cleaner(
scripts=True, # Удаляет все js скрипты <script>
comments=True, # Удаляет все комментарии
allow_tags=['br', 'td', 'tr', 'img'], # Список тэгов которые не нужно удалять
remove_unknown_tags=False
)
print(
cleaner.clean_html( # применяем фильтр
html.tostring(
item,
encoding='unicode'
)
)
)
print()
# Ищем элемент td выровненный по центру
item_td = item.cssselect('td[align=center]')[0]
print(
html.tostring(
item_td,
encoding='unicode'
)
)
print()
# Удаляем все атрибуты корневого тэга
item_td.attrib.clear()
print(
html.tostring(
item_td,
encoding='unicode'
)
)
print()
# Меняем название тэга
item_td.tag = 'my_custom_tag_td'
print(
html.tostring(
item_td,
encoding='unicode'
)
)
print()
# Удаляем список тегов, не трогая их содержимое
etree.strip_tags(item_td, 'a', 'b', 'c')
print(
html.tostring(
item_td,
encoding='unicode'
)
)
print()
# Удаляем тэг со всеми потрахами
etree.strip_elements(item_td, 'td')
print(
html.tostring(
item_td,
encoding='unicode'
)
)
print()